NVIDIA RTX 5090 vs H100: Which one to choose for AI?
💡 Quick Tip
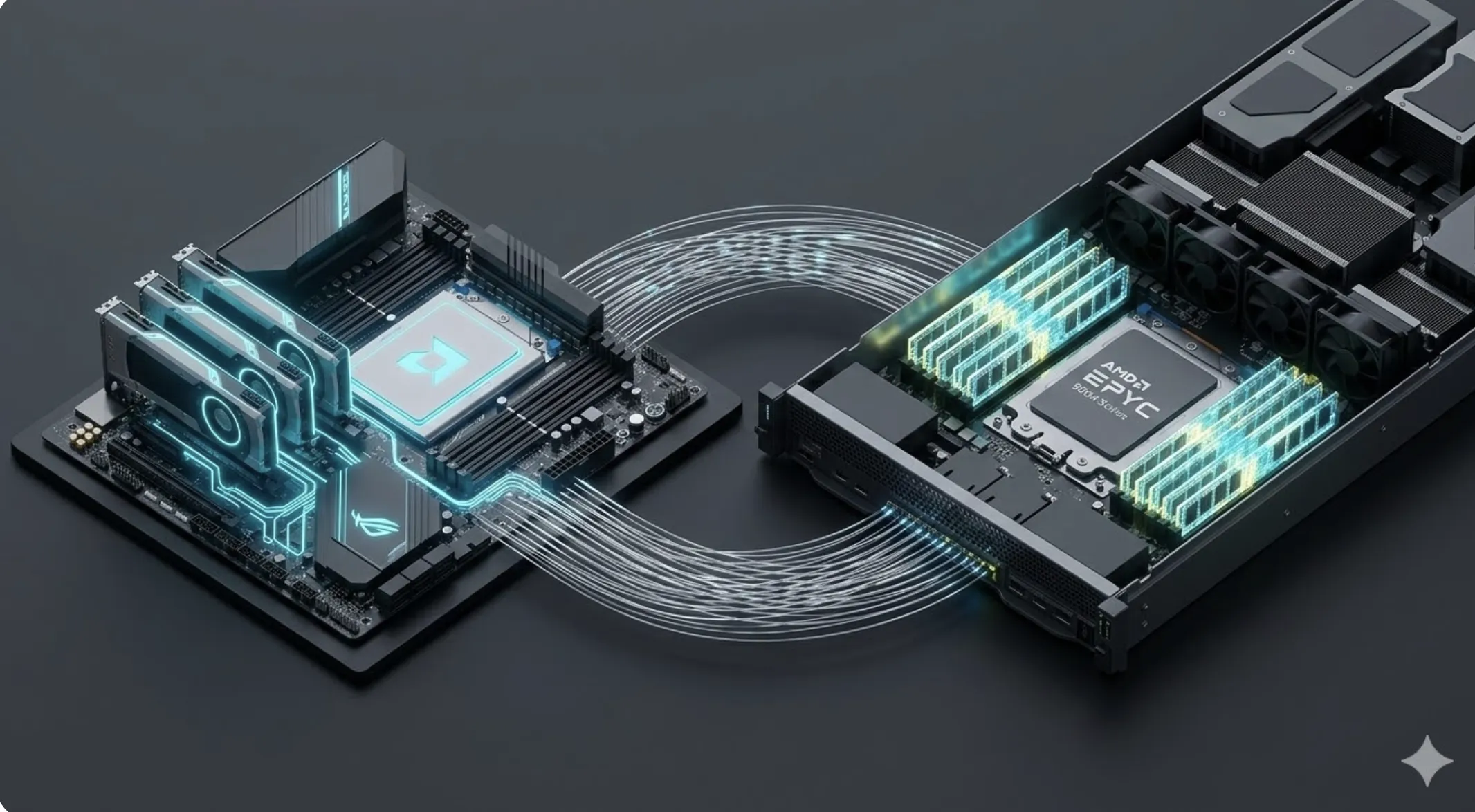
RTX 5090 or H100 for your AI projects? In 2026, the gap between professional consumption and industrial infrastructure is defined by HBM3e memory and massive NVLink interconnectivity.
The ENIAC and the Birth of Industrial Computing
In 1945, the ENIAC occupied an entire room and consumed 150 kW for ballistic calculations. It was the start of industrial-scale computing. Today, the NVIDIA H100 is the heir to that massive power, while the RTX 5090 represents the democratization of that power on the desktop. Real engineering consists of knowing when you need a jet engine (H100) and when you need a precision engine for prototyping (RTX 5090). It is the difference between building a model and scaling an AI civilization.
The Thesis: The High-End GPU as an Expensive Remote Control
Using an RTX 5090 to try to train a foundational model from scratch is, in practice, using an expensive remote control. You have amazing power in your hands, but the lack of HBM3e memory and enterprise-grade interconnect bandwidth will limit your results. The 5090 is an elite tool for development and fine-tuning, but the H100 is the piece of infrastructure that allows structural AI to be a global reality.
The Diagnosis: VRAM Islands and the Communication Wall
The problem with domestic multi-GPU setups is VRAM islands. Without the massive NVLink bandwidth present in the H100 series, cards cannot share memory efficiently. According to Cinto Casals, AI Architect, this fragments the model into silos, forcing engineers to waste time optimizing communication instead of intelligence itself.
Future Vision: The Invisible Technology of Hybrid Clusters
The future leads us to invisible technology, where the developer uses their local RTX for coding and the H100 cluster in the cloud activates automatically for heavy processing. In 2026, the AI-Native software layer will manage this transition proactively, eliminating friction between desktop and data center hardware.
📊 Practical Example
Real Scenario: From Fine-Tuning to Global Inference
An AI startup uses the RTX 5090 to fine-tune its models locally. Upon launching the service for thousands of simultaneous users, they migrate to H100 clusters, the only ones capable of handling massive inference with low latency.